Recherche Sémantique
Les Bases de Données Vectorielles, Révolutionnaires !
Ecrit par Chaima, Vincent
Chez Eurelis, nous sommes convaincus que :
Les bases de données vectorielles constituent une évolution majeur des pratiques d’indexation et d’accès aux données. Cette technologie présente un potentiel d’innovation prêt à être exploré.
Experts Eurelis
C’est à travers l’immense quête de pertinence numérique qu’émergent les bases de données vectorielles, une avancée majeure marquant un progrès technologique significatif dans notre façon de manipuler les données et ouvrant la voie à de nouveaux modes d’intéraction avec le monde numérique.
Ces bases de données adoptent une méthode révolutionnaire de gestion et d’analyse de l’information, notamment pour le traitement des données complexes. Sous l’impulsion du Machine Learning et de l’Intelligence Artificielle, elles ouvrent la voie à de nouvelles applications, notamment dans la compréhension et le traitement du langage naturel.
Qu’est-ce qu’une Base de données vectorielle ?
Définition
Une base de données vectorielle est une solution conçue pour stocker, interroger et manipuler des données sous forme de vecteurs. Un vecteur dans ce contexte est une représentation numérique encapsulant les caractéristiques fondamentales de ces données, encodées dans un tableau de nombres. Ce vecteur positionne ainsi l’objet dans un espace multidimensionnel, permettant ainsi les recherches basées sur les similarités.
Voici quelques aspects clés des bases de données vectorielles :
1 – Représentation des données: Les données, telles que des images, du texte ou des sons, sont transformées en vecteurs de caractéristiques. Chaque vecteur peut représenter divers attributs ou caractéristiques d’un objet ou d’une entité.
2 – Recherche efficace: Les bases de données vectorielles sont optimisées pour les requêtes de recherche basées sur la similarité. Elles utilisent des méthodes de recherche dans des espaces vectoriels pour trouver rapidement les éléments les plus similaires à une requête donnée, souvent en utilisant des métriques de distance comme la distance euclidienne ou la similarité cosinus.
3 – Technologies: Plusieurs technologies peuvent être utilisées pour implémenter des bases de données vectorielles, incluant des index spécialisés comme les arbres KD, les graphes de proximité approximative, ou d’autres structures de données qui supportent des requêtes de voisinage les plus proches.
Ce type de base de données est particulièrement utile dans les domaines de la recherche d’information, du traitement automatique des langues, de la reconnaissance d’images et de la recommandation de produits, où la capacité de comparer des éléments sur la base de caractéristiques similaires est cruciale.
L’encodage
Une des principales difficultés réside dans l’encodage, ou la création de l’embedding, qui requiert des algorithmes spécifiques. Voici quelques exemples :
1 – Réseaux de neurones profonds: Ces modèles sont fréquemment utilisés pour transformer des données brutes en vecteurs denses. Par exemple, les réseaux de neurones convolutifs (CNN) sont utilisés pour les images, tandis que les réseaux de neurones récurrents (RNN) ou les transformateurs sont utilisés pour le traitement du langage naturel.
2 – Word Embeddings: Pour le texte, des modèles comme Word2Vec, GloVe, ou FastText apprennent à représenter les mots sous forme de vecteurs de manière à ce que les mots ayant des significations similaires aient des vecteurs proches dans l’espace vectoriel.
3 – Auto-encodeurs: Ces réseaux de neurones sont formés pour compresser les données d’entrée dans une représentation plus petite (encodeur) avant de les reconstruire à partir de cette représentation (décodeur). La partie de compression est utilisée pour générer les vecteurs.
4 – Modèles pré-entraînés: Pour de nombreuses applications, les praticiens utilisent des modèles déjà entraînés disponibles publiquement, tels que BERT pour le texte ou ResNet pour les images, pour extraire des vecteurs caractéristiques sans avoir à former un modèle à partir de zéro.
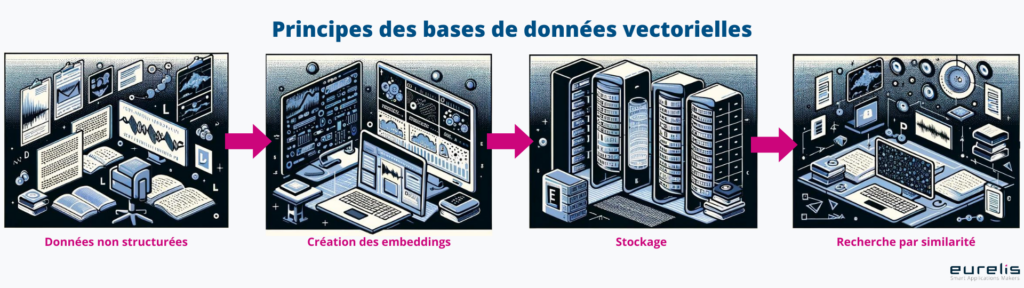
Comment fonctionne une BDD vectorielle ?
Une base de données vectorielle, spécialisée dans le stockage et la manipulation de vecteurs, fonctionne de manière à optimiser les opérations de recherche et de comparaison de données vectorielles. Voici les principes clés de leur fonctionnement:
1 – Stockage des vecteurs: Les données brutes (textes, images, sons, etc.) sont transformées en vecteurs numériques via les processus de modélisation décrits plus haut. Ces vecteurs sont ensuite stockés dans la base de données. Ce stockage est optimisé pour permettre des recherches rapides et efficaces.
2 – Indexation: Pour accélérer les requêtes de recherche, les bases de données vectorielles utilisent des techniques d’indexation avancées. Ces indices ne se contentent pas de stocker les vecteurs, mais organisent l’espace vectoriel de manière à optimiser les recherches de proximité. Des structures d’index comme les arbres KD, les graphes de proximité approximative (APG), ou les hashings locaux sensibles (LSH) sont couramment utilisées.
3 – Recherche de similarité: L’un des principaux avantages des bases de données vectorielles est leur capacité à effectuer des recherches basées sur la similarité. Lorsqu’une requête est soumise sous la forme d’un vecteur, la base de données utilise des mesures de distance (comme la distance euclidienne, la distance de Manhattan, ou la similarité cosinus) pour trouver les vecteurs les plus proches (ou les plus similaires) dans la base de données.
Comment choisir une BDD vectorielle ?
À présent, il est clair que les bases de données vectorielles présentent un potentiel immense. Cependant, le choix de la plateforme la plus appropriée dépend de plusieurs facteurs internes (besoins du projet) et externes (contraintes budgétaires et ressources) . Voici comment ces éléments peuvent influencer votre décision :
Facteurs internes
- Type de Données: Quelle est la nature des données ? Images, texte, audio, vidéo ? Les données nécessitent-elles un traitement spécial, comme des embeddings ou des transformations complexes ?
- Volume de Données: Quelle est la taille prévue de la base de données ? La base doit-elle gérer de gros volumes de données entrantes en continu ?
- Performance des Requêtes: Quels sont les besoins en termes de latence et de débit des requêtes ? La base de données doit-elle supporter des requêtes en temps réel ou des charges de travail batch ?
- Évolutivité: Le système doit-il être facilement scalable, tant verticalement qu’horizontalement ? Quels sont les besoins en termes de gestion de la croissance des données ?
- Sécurité et Conformité: Quelles sont les exigences en matière de sécurité et de confidentialité des données ? La base de données doit-elle respecter des normes réglementaires spécifiques ?
- Budget: Quelles sont les contraintes budgétaires pour le développement et la maintenance ? Le coût de la licence, de l’hébergement et de l’exploitation est-il en ligne avec le budget du projet ?
- Alignement avec les objectifs spécifiques du projet : Réfléchir à la manière dont la base de données vectorielle peut soutenir et améliorer les objectifs à long terme de votre projet, en termes de performance, d’efficacité et de résultats attendus.
Facteurs externes
- Maturité du Produit: Le produit est-il éprouvé avec une base d’utilisateurs substantielle ? Y a-t-il des études de cas ou des témoignages d’autres entreprises similaires ?
- Interopérabilité et Écosystème: La base de données s’intègre-t-elle facilement avec d’autres outils et technologies déjà utilisés dans l’entreprise ? Existe-t-il des plugins ou des extensions qui ajoutent des fonctionnalités utiles ?
- Facilité de Déploiement et de Maintenance: Quelles sont les exigences pour le déploiement et la maintenance de la base de données ? La base de données nécessite-t-elle des compétences spécifiques ou rares pour sa gestion ?
- Innovation et Mises à Jour: Le fournisseur de la base de données investit-il dans la recherche et le développement ? À quelle fréquence les mises à jour sont-elles publiées et quelles améliorations offrent-elles ?
- Support et Communauté: La base de données est-elle largement adoptée et soutenue par une communauté active ? Quel est le niveau de support technique disponible ?
Les principales solutions de BDD vectorielles
Il existe de nombreuses solutions de bases de données vectorielles sur le marché, chacune avec ses propres caractéristiques et avantages. En plus des plateformes spécialisées dans cette approche, les principaux SGBD proposent maintenant un support pour les approches vecttorielles.
Voici quelques-unes des solutions les plus populaires et les plus performantes :
- Milvus se distingue par sa capacité à gérer de grandes bases de données vectorielles, avec des améliorations notables en termes de performance de requête et de scalabilité. Milvus est très apprécié pour sa nature open-source et son fort soutien communautaire.
- Pinecone offre une plateforme évolutive et facile à utiliser, bien qu’elle ne soit pas open-source. Elle est reconnue pour ses performances élevées et ses faibles latences, idéale pour les applications de recherche vectorielle.
- Qdrant représente une option intéressante, notamment pour les projets avec des contraintes budgétaires, grâce à son prix compétitif. Il supporte une large gamme de types de données et de critères de requête, et est noté pour sa simplicité et sa configurabilité.
- Weaviate est une autre base de données vectorielle open-source qui s’intègre facilement avec les modèles de machine learning, offrant des capacités comme la vectorisation automatique de textes et d’images et supportant GraphQL.
- Chroma offre également des fonctionnalités spécialisées dans la gestion de bases de données vectorielles, avec le support de plusieurs métriques de distance, comme la distance euclidienne et la similarité cosinus, ce qui permet d’effectuer des recherches précises dans des ensembles de données complexes.
- Elasticsearch reste un acteur clé, particulièrement adapté pour ceux qui ont besoin d’une solution robuste et distribuée capable de gérer des données textuelles, numériques et vectorielles. Il est bien adapté pour des applications nécessitant une haute disponibilité et une grande capacité de montée en charge.
Les choix d’Eurelis
- MongoDB Atlas Search, intégré dans la plateforme MongoDB Atlas, permet d’effectuer des recherches vectorielles en utilisant des fonctionnalités telles que la recherche par similarité vectorielle basée sur le produit scalaire, la cosine similarity, et la distance euclidienne. Cette solution est adaptée pour les applications nécessitant une intégration avec des bases de données documentaires et la gestion de données semi-structurées ou non structurées.
- Solr, basé sur Apache Lucene, a récemment intégré des capacités de recherche vectorielle à ses fonctionnalités de recherche textuelle traditionnelles. Il supporte des opérations de recherche vectorielle utilisant différentes métriques de distance telles que l’euclidienne, le produit de points et la similarité cosinus. Solr est adapté pour les applications nécessitant des recherches hybrides combinant texte et vecteurs, et il peut gérer un grand nombre de dimensions dans ses champs vectoriels.
Eurelis a développé le connecteur langchain-solr-vectorstore permettant l’utilisation de Solr en tant que Vector Store depuis le framework Langchain.
Vous aspirez à concevoir ou améliorer un système de recherche d’information sur mesure ? un moteur de recherche plus précis ? un chatbot pertinent ? ou un système de recommandation personnalisé ?
Passez à l’Action et Trouvez l’Expertise Dont Vous Avez Besoin avec Eurelis !
Eurelis, Votre Expert en Intelligence Artificielle vous accompagne étape par étape dans la réalisation de vos projets les plus ambitieux !
Embarquez dans cette aventure et faites évaluer votre projet par un expert Eurelis ! 🚀
Si vous avez manqué le début…
- Article 0 : Transformer l’information en Innovation. Un voyage à travers les Évolutions des Systèmes de Recherche d’Information.
- Article 1 : Systèmes de Recherche d’Information: De l’Indexation à la Compréhension !.
- Article 2 : Compréhension Structurée – L’Évolution des Bases de Données et de la recherche !
Stay Tuned pour la suite de la série !
- Article 4 : Révolutions de l’IA – Avancées dans les Modèles de Langage
- Article 5 : Potentiel amplifié par l’IA – Opportunités du Couplage entre les LLM et les BDD Vectorielles
Références
Picking a vector database: a comparison and guide for 2023
https://benchmark.vectorview.ai/vectordbs.html
Comparing Vector Search Solutions 2023
https://pureinsights.com/blog/2023/comparing-vector-search-solutions-2023/
Benchmarking nearest neighbors
https://github.com/erikbern/ann-benchmarks